前情提要: 前面兩篇透過einops來提高model的可讀性。
之所以會一直沒有講到model怎麼寫,是因為每個model架構在不同領域其實相差蠻多的,我在思考怎麼樣透過一個例子,來幫助碩班學生更好進入這個領域,最後我選擇用我最一開始做過的語音增強(speech enhancement)來講。
雖然很多時候都是拿人家做過的再做一次,但透過實作來學習一定是最快的,透過看別人的code,加上自己重寫,可以思考為甚麼要這樣,以及能不能再優化,在學習階段我覺得非常畢業。
參考github: ( https://github.com/facebookresearch/denoiser )
論文: https://arxiv.org/pdf/2006.12847
DEMUCS最一開始是由facebook提出 (https://github.com/facebookresearch/demucs )主要是做語音分離的,基本上語音分離跟語音增強model架構是差不多的,只差在最後輸出而已。
CNN觀念: https://blog.csdn.net/thy0000/article/details/133586386
範例採用最簡單,time domain的DEMUCS,這裡主要有time domain跟time-frequency domain,一個是直接輸入torchaudio的data,另一個是torchaudio完再用stft轉,那time domain模型相對簡單很多,而且我當初會做這個主要原因,是time domain比較不會破壞波形,凡是增強和分離完的音檔一定會破壞波形,有些可能人耳聽不出來,但如果送到ASR的話就會有問題。
此架構其實就是unet,主要分成四個部分:
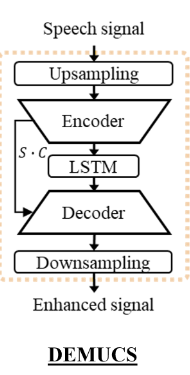

如果是time domain那麼資料是一維的,如果是time-frequency資料會是二維,一維的使用Conv1d,我們參照論文當中的架構圖,主要每一層就是兩個Conv1d,搭配ReLU跟GLU
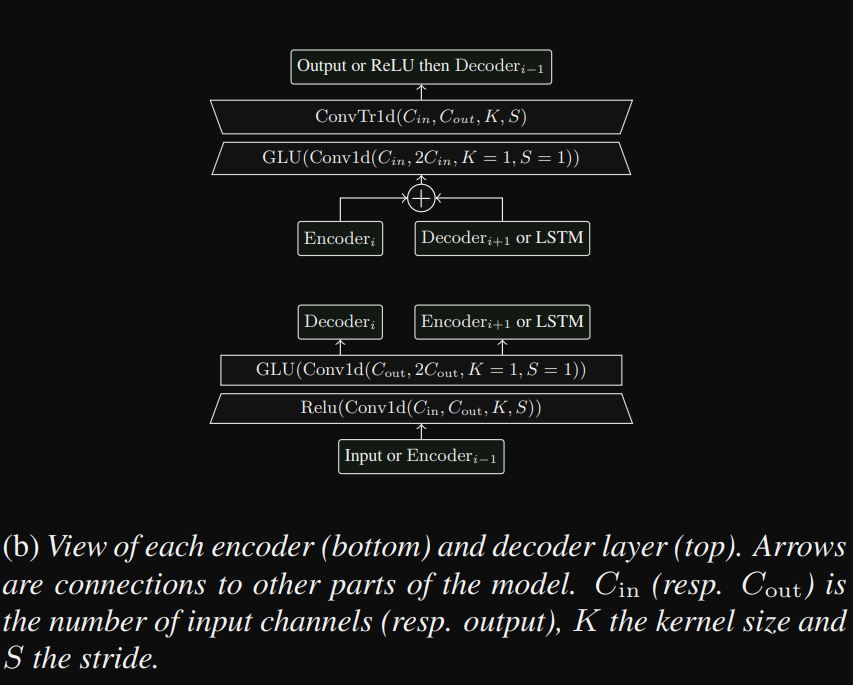
首先我們先寫一個class叫DoublConv,主要就是每一層所需要的
import torch
import torch.nn as nn
import math
from torch.nn import functional as F
class DoublConv(nn.Module):
def __init__(self, chin, hidden, K, S):
super().__init__()
self.DoublConv = nn.Sequential(
nn.Conv1d(chin, hidden, K, S),
nn.ReLU(),
nn.Conv1d(hidden, hidden * 2, 1, 1),# 這裡輸出乘2是因為底下使用GLU
nn.GLU(1)
)
def forward(self, x):
return self.DoublConv(x)
再來就是寫Encoder,主要就是用for迴圈然後將五層需要的DoubleConv append進去,每一層append完之後調整chin跟hidden。
當中的valid_length是我直接copy github上面的,主要就是將最右邊padding 0,讓整個運算是有效卷積。
class Encoder(nn.Module):
def __init__(
self,
chin = 1,
hidden = 48,
kernel_size = 8,
stride = 4,
growth = 2,
depth = 5,
):
super().__init__()
self.kernel_size = kernel_size
self.stride = stride
self.depth = depth
self.encoder = nn.ModuleList()
for _ in range(depth):
self.encoder.append(DoublConv(chin, hidden, kernel_size, stride))
chin = hidden
hidden *= growth
def valid_length(self, length):
"""
Return the nearest valid length to use with the model so that
there is no time steps left over in a convolutions, e.g. for all
layers, size of the input - kernel_size % stride = 0.
If the mixture has a valid length, the estimated sources
will have exactly the same length.
"""
# length = math.ceil(length * self.resample) # 128000
for idx in range(self.depth):
length = math.ceil((length - self.kernel_size) / self.stride) + 1
length = max(length, 1)
for idx in range(self.depth):
length = (length - 1) * self.stride + self.kernel_size
# length = int(math.ceil(length / self.resample))
return int(length)
def forward(self, x):
length = x.size(-1)
x = F.pad(x, (0, self.valid_length(length) - length))
for idx, enc in enumerate(self.encoder):
x = enc(x)
print(f'idx: {idx}, x: {x.size()}')
return x
if __name__ == "__main__":
x = torch.rand(2, 1, 16000)
encoder = Encoder()
print(encoder)
x = encoder(x)
print(x.shape)
到目前為止就把Encoder的部分完成囉,我自己寫model到最後會把它拆解成一個個block,如果是重複使用的會寫成class,雖然比較麻煩,但對於可讀性是大大增加。
今天就先到這裡囉~~ 因為程式是重新寫過,有可能會有錯,如果有錯歡迎提出。


 iThome鐵人賽
iThome鐵人賽